

今天看到朋友发 Karpathy 的 LLM Wiki,心痒难耐,结合他的推特,最后用Claude code 折腾一通,把我们业务相关的政策折腾一通,非常舒适。
我其实之前就想弄这个,但我思路还比较简单,就是把政策资料喂给 AI,让它按照 What-Why-How 格式来写文档,后面如果我需要调取哪个文档,就手动查找,让AI来处理,查资料,写文章,等等。缺点是依赖人力,我每次都要亲自操作,然后如果项目有改动,我又不知道要如何处理。
而Karpathy的厉害之处在于,他让 AI 维护好三个文档就够了:
schema.md:概要,解释这个文档是干什么用的,AI一读,就知道如何操作,如文档目录、笔记结构、属性规范、工作流程,极为明确(这个文件也可能叫CLAUDE.md)。index.md:索引,我刚才说之前有过要按照项目分门别类梳理文档的意识,可没有用一根绳子串联起来,而index起的就是这个作用,就像维基百科那样,它会将wiki文件夹里的文档逐个梳理好,一行内容有可以点击的双向链接,后面是简要解释。由于它会把所有页面列入其中,还会贴心地做分类,这等于你只需要查看这一页,就知道有哪些概念log.md:日志,用来记录操作日志,方便回溯。我的理解是,它就像一个每天凌晨就会重置记忆的人写下来的笔记本,害怕自己第二天忘记之前做了什么,就拼命写下,等到次日再从头到尾看日志,就知道过去做了什么,对于 AI 来说,你切换对话,或者换成其他大模型,也能继续工作。
三份文档是底层原理,结合之下,解决过去我们和大模型聊天时,换了一个对话,就要反复发资料,抑或得到资料后,用完即走,等到下次需要,又要翻找对话。如今有了 wiki,一切均已打通,资料只要沉淀下来,就能作为养料,将来待查找时,也不搜索,而是直接询问 AI,钩沉索隐变得如此轻易。
下面可以聊聊我是怎么用的。诚然,在推特和公众号上,已有无数人分享实操方法,笔者不在此赘述。简要来说,即把文章开头的两个链接内容,喂给你的 Claude Code(国产大模型亦可),让其根据你的文件库来给思路。
它通常会建两个文件夹:wiki/ 和 raw/。
先说 raw/,就是把你的资料都放在这下面,比如剪藏的网页文章,又或者行业政策、新闻,反正是你所关心的、所需要的,都能存进去,最好是 md 文件。你可以用 Chrome 插件 Obsidian Web Clipper 剪藏网页——在过去,它能让你结合笔记库查资料,现在则是作为 AI 的素材。
今天恰好跟朋友聊到写作,我找来几篇文章,做个 wiki 来举例。
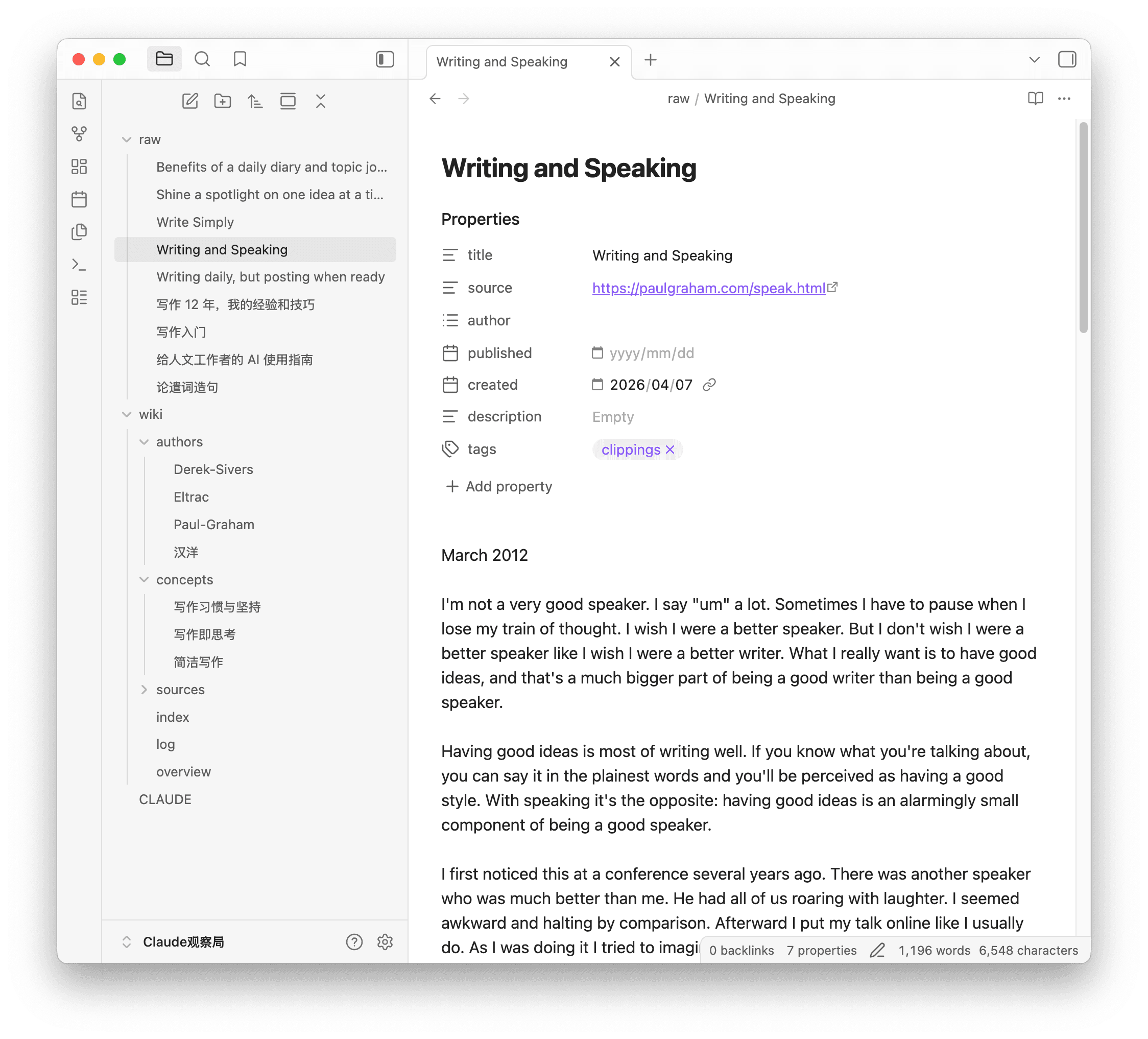
有了素材后,你就能让 Claude Code 针对它 ingest(摄入)。AI 先梳理目录,读取文件,然后自动整理成词条,你什么都不用做,没一会儿就看到词条突突往外冒。index.md 有了词条索引,就像维基百科那样,点击就能查看。
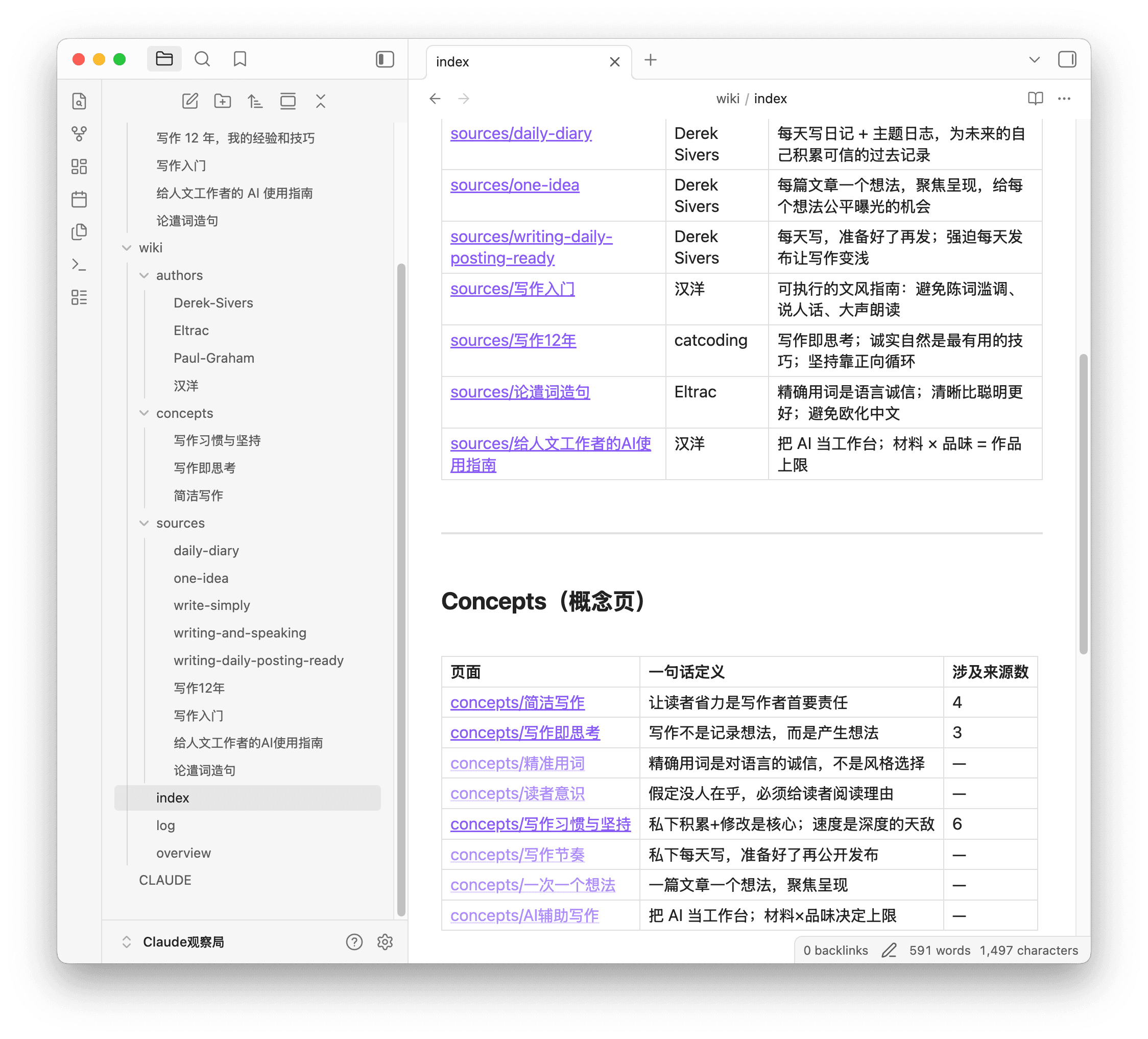
当 wiki/ 库略微充实后,就到下一步。
你可以直接问问题,测试效果如何,或者写稿时查找资料,因为它只会根据已有的词条来回答,也就避免胡编乱造(即 AI 的幻觉)。后面如果有新的资料要纳入,那只需要让 Claude Code 继续 ingest,wiki/ 便会自动更新,一切过往都能从 log.md 查看。
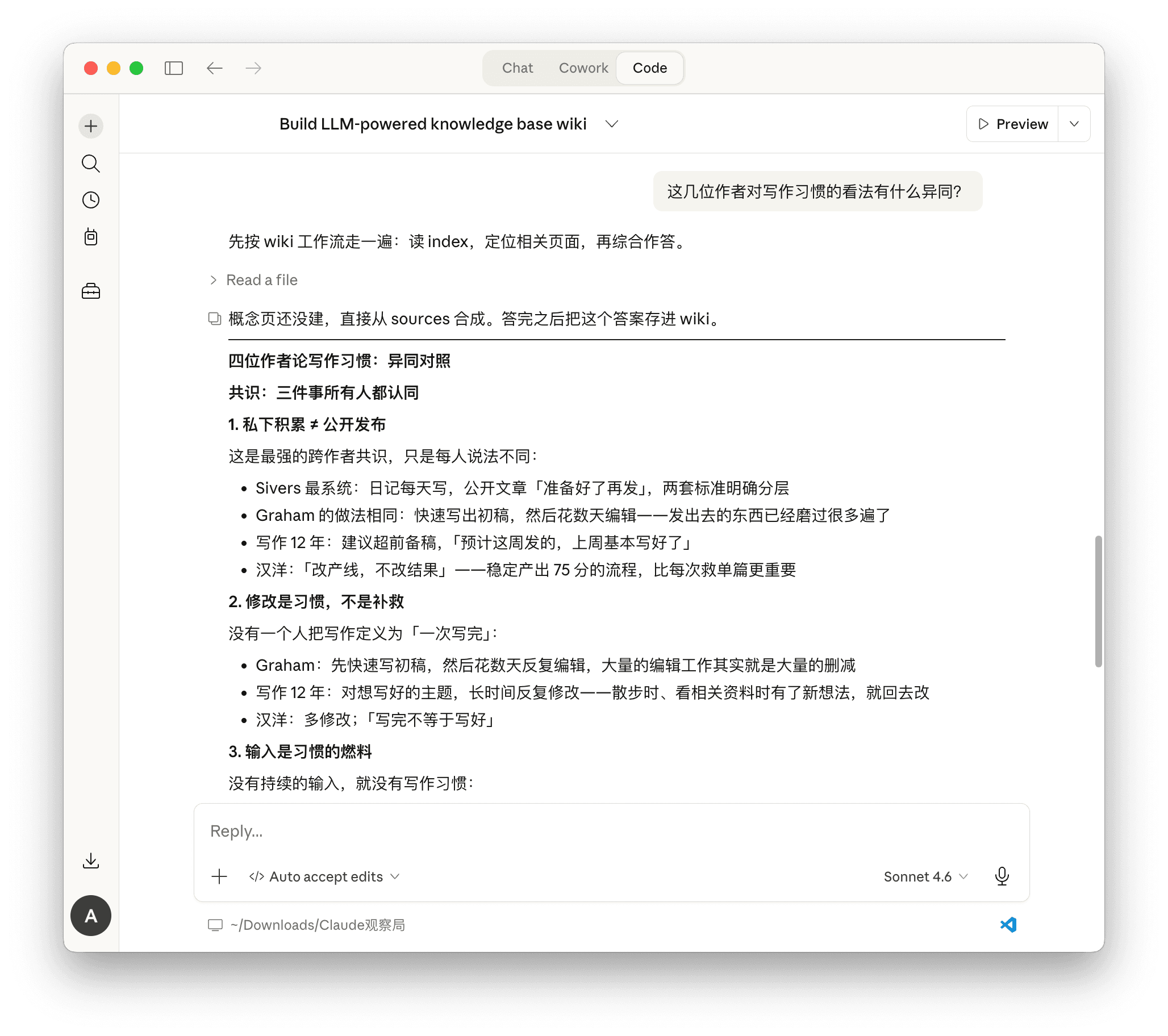
这一天折腾下来,乐趣无穷。惜乎额度有限,一天耗完后只能等下次重置时间,而如果一周消耗完,那就只能干看着发愣。我用 kimi 2.5 作为辅助,如果文件一看有好几万字,就让它来代劳,可谓便宜好使。
今天所写,还比较粗浅,也只是一下午的折腾心得,后面如果雪球越滚越大,效果还未可知。但已有朋友准备把日记、文章、知识库等东西让 Claude 跑一通,我算了算,直言「不敢想、不敢跑」。
庄子曾言:「吾生有涯,而知无涯」,如今在 AI 井喷时代,折腾 AI 也无止境矣。